
Fusion multimodalité
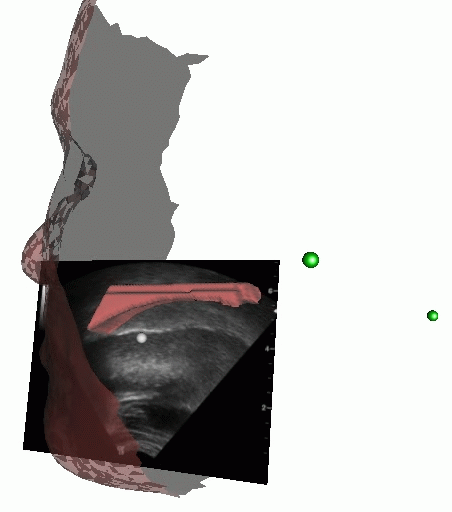
Nous travaillons à la construction d'un modèle articulatoire dynamique à partir d'images ultrasonores, vidéos, IRM et à partir de capteurs magnétiques. L'objectif est de construire une tête augmentée intégrant les articulateurs externes (lèvres) et internes (langues). Les applications de ces travaux concernent l'apprentissage des langues.
Acquisition et fusion de données multimodales
|
|
Modélisation d'une tête parlante réaliste
L'objectif est d'animer de façon très réaliste une tête dense. Dans notre approche, la dynamique du visage est acquise sur un corpus sparse obtenu en peignant des marqueurs sur le visage. Cette dynamique est ensuite transférée sur le visage dense.
|

|




copyright INRIA / Photos C. Lebedinsky