A Semi-Automatic Method for Resolving Occlusions in Augmented Reality
| The objective of Augmented Reality (AR) is to add virtual objects
to real video sequences. In order to make AR system effective, the computer-generated
objects and the real scene must be combined seamlessly so that the virtual
objects align well with the real ones. Realistic merging of virtual and
real objects also requires that objects behave in a physical plausible
manner in the environment : they can be occluded or shadowed by objects
in the scene.
Few of AR systems address the occlusion problem. Theoretically, resolving occlusions amounts to compare the depth of the virtual objects to the depth of the real scene.
|
 |
Overview
We suppose that the viewpoints and their uncertainties have been computed over the sequence (click here for details). Here is a description of our method :![]() First, the user outlines
the occluding objects in a small set of selected frames (see Figure 1,
a and b). These key frames correspond to views where aspect changes occur,
like the apparition of a new facet of an occluding object.
First, the user outlines
the occluding objects in a small set of selected frames (see Figure 1,
a and b). These key frames correspond to views where aspect changes occur,
like the apparition of a new facet of an occluding object.
![]() We build the 3D occluding
boundary of the occluding object from two consecutive key frames (Fig 1.c).
(details).
We build the 3D occluding
boundary of the occluding object from two consecutive key frames (Fig 1.c).
(details).
![]() The projection of this
3D curve is used to predict the 2D occluding boundary in the frames between
the two key views. Since we take into account of the uncertainty on the
viewpoints during the reconstruction and the projection phases, we also
get a region
The projection of this
3D curve is used to predict the 2D occluding boundary in the frames between
the two key views. Since we take into account of the uncertainty on the
viewpoints during the reconstruction and the projection phases, we also
get a region ![]() i around each
point of the predicted boundary, which contains the actual point position
(Fig. 1.d). (details)
i around each
point of the predicted boundary, which contains the actual point position
(Fig. 1.d). (details)
![]() The predicted boundary
is refined, under the constraint that the recovered boundary points must
be in their
The predicted boundary
is refined, under the constraint that the recovered boundary points must
be in their ![]() i region, using
a region-based tracking, and an active contour model (Fig. 1.e). (details)
i region, using
a region-based tracking, and an active contour model (Fig. 1.e). (details)
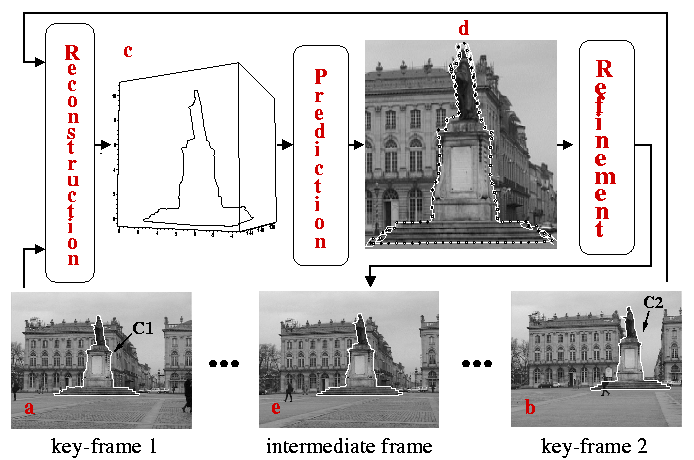
Figure 1: Overview of the occlusion resolution system
![]()
Results
 The Stanislas Sequence
The Stanislas Sequence
The Stanislas sequence was shot from a car which moved around the square.

The |

The recovered occluding boundaries |

Another representation |

A first augmented sequence |

Another augmented sequence |

Another one (just for fun) |
![]()
![]() The cow Sequence
The cow Sequence
This sequence has been used to test our algorithm with a relatively
complex occluding object and a rotating camera. So the apparence of the
occluding object (the cow) changes sensitively over the sequence. A calibration
table has been used to recover the camera trajectory, this way the viewpoints
are almost exact. The three key views were:

Key view 1 |

Key view 2 |

Key view 3 |

The augmented sequence |
![]()
![]() The return
of the cow
The return
of the cow
This sequence differs from the previous sequence by several points:
the viewpoints have been recovered with our hybrid
method (which uses only images features); the camera trajectory is
more general; the occluding object (yes, a cow again) is more complex.
Since the cow paws appear and disappear, we had to define five key views
at the beginning of the sequence. But key-views 5 and 6 are distant.

Key view 1 |

Key view 2 |

Key view 3 |

Key view 4 |

Key view 5 |

Key view 6 |

The augmented sequence |
![]()
![]() The Loria
Sequence
The Loria
Sequence
In this sequence, the dominant motion of the camera is a translation
along the optical axis. Such a motion is known to be difficult both for
motion recovery and 3D reconstruction, but the refinement stage succeed
in recovering the actual boundary in nearly all cases. However, some problems
arise at the end of the sequence when the light post is going to leave
the image.We used only two key views :

Key frame 1 |

Key frame 2 |

The augmented sequence (4Mo) |

The augmented sequence (frames 240 to 480 - 1.4 Mo) |